

Background: Sickle cell disease (SCD) is the most common inherited hemoglobinopathy worldwide. The pathophysiology of the disease results in end organ damage which leads to morbidity and mortality. In a subset of patients, SCD-related complications have resulted in prolonged hospitalizations and increased frequency of 30-day hospital readmissions. In the era of value-based health care, hospital quality metrics and reimbursements are generated based on strategic health care utilization. Therefore, being able to identify early unplanned hospital readmissions is critical in managing health care expenditure.
Objective: To develop machine learning algorithms for predicting the 30-day unplanned readmission risk of SCD patients and to compare the predictive power of machine learning models against standard hospital readmission scoring systems.
Methods: We analyzed retrospective real-world electronic health records (EHR) data for patients with SCD at our institution from January 1, 2013- November 1, 2018. The raw data set contained 2824 unique SCD patients from across 5 hospitals within the University of Pittsburgh Medical Center. After preprocessing using our inclusion criteria, our cohort included 3299 admissions comprising of 446 adult SCD patients. Features extracted from the EHR data were reduced and regrouped using both data-driven methods and clinical knowledge, resulting in 486 unique features. Logistic Regression (LR), Support Vector Machine (SVM), and Random Forest (RF) were applied to predict for 30-day unplanned hospital readmissions in SCD. Prediction performance was evaluated using the area under the receiver operating characteristic curve (AUC), sensitivity and specificity. We compared our results against standard hospital readmission prediction tools such as LACE and HOSPITAL indices.
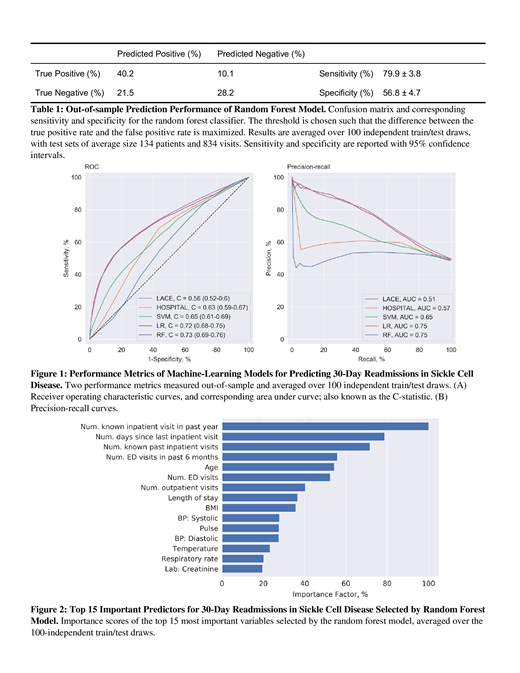
Results: We randomly selected the inpatient admissions incurred by 30 percent of the 195 return patients and 251 nonreturn patients to be included in the testing set (n = 134); the training set contained the inpatient admissions incurred by the remaining 211 patients. Thus, our training and testing sets contained similar demographic information, predictors, and outcomes. The average number of admissions was 7.40 (12.90) for the 446 patients, and 14.47 (16.97) for the 195 patients who had 30-day readmissions. Since the number of samples in our study is comparatively small, our results might be sensitive to the training and testing splits. To address this problem, we performed 100 different training and testing splits and averaged the resulting 100 AUCs.
Figure 1 summarizes the two performance metrics of each model. The two benchmark prediction tools, LACE and HOSPITAL, have AUCs of 0.56 (95%CI 0.52-0.60) and 0.63 (95%CI 0.59-0.67), respectively. Notably, all three machine learning algorithms outperformed both benchmarks. The RF was the best machine learning model in prediction of hospital readmissions, as reported in similar machine learning studies (Deschepper et al. 2019), with an AUC of 0.73 (95%CI 0.69-0.76). Table 1 summarizes the sensitivity and specificity of our RF model.
Conclusion: Machine learning algorithms outperformed the standard hospital readmission risk scoring systems, LACE and HOSPITAL, by a large margin in a real world data set of SCD patients at a single institution. In particular, machine learning algorithms were able to identify important variables that are underrepresented in the traditional risk scoring systems (Figure 2). The use of machine learning algorithms can be a powerful tool in providing valuable insight towards health care expenditure and resource allocation in high risk patient groups.
No relevant conflicts of interest to declare.

This feature is available to Subscribers Only
Sign In or Create an Account Close Modal